

社内ドキュメントをAIエージェントに渡したい。
そう考えてWikiを開いてみたものの、どこから手を付ければいいか分からず、結局そのまま閉じてしまった経験はないでしょうか。
Notionもある、共有ドライブもある、でもどれも中途半端。
そんな状態で「どう構造化すればいいの?」と悩んでいる開発者やライターの方は、少なくありません。
2026年6月にGoogle Cloudが公開したOpen Knowledge Format(OKF)v0.1は、まさにこの「どこから整えるか」を最初に決めるためのフォーマットです。
仕様書は約450行。
読むだけなら30分もかからないシンプルさですが、実際に手を動かす前に理解しておくべきポイントがいくつかあります。この記事では、OKFの全体像を把握してから、最小バンドルを実際に書いてみるまでの流れを、つまずきやすい箇所も含めて整理しました。
OKFの全体像:5つの構成要素を先に把握する

 長谷川さん
長谷川さんOKFって、結局何をどう書けばいいんですか…?
仕様書読んでも全体像がつかめなくて
 高野さん
高野さん順番が逆なんだよね。
書き方より先に「5つの構成要素」を頭に入れた方が早いよ
OKFは、YAMLフロントマター付きのMarkdownファイルをディレクトリに置く、というシンプルな構造です。ただ、何も知らずに書き始めると「これでいいのか?」と不安になる箇所が出てきます。
最初に全体像を把握しておけば、迷わず手を動かせます。
OKFは大きく5つの要素で構成されています。
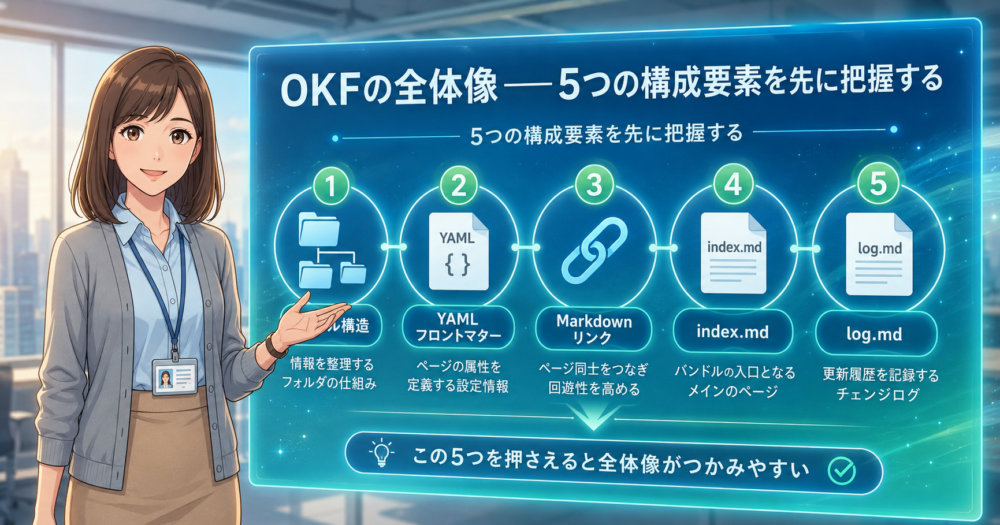
バンドル構造、YAMLフロントマター、Markdownリンク、index.md、log.md。この5つがどう組み合わさるかを先に理解しておくと、仕様書の細かい記述も腑に落ちやすくなります。
全体を把握せずに書き始めると
- ディレクトリをどう切るか
- どのファイルにどのメタデータを書くか
- リンクをどうつなぐか
という判断で止まってしまいがちです。
最初に5つの役割を押さえておくだけで、作業の見通しが立ちます。
バンドル構造:ディレクトリツリーで知識を階層化
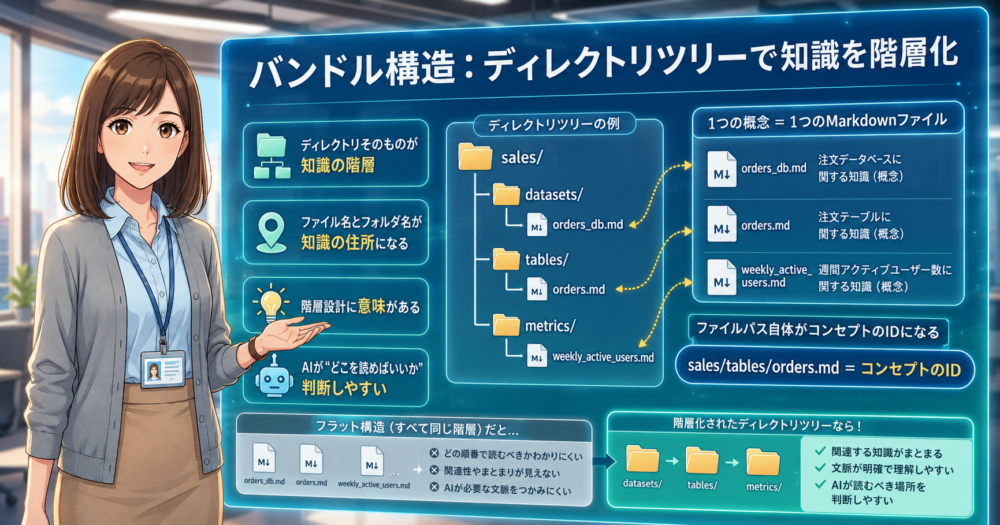
OKFではディレクトリそのものが知識の階層を表します。
1つの概念(コンセプト)を1つのMarkdownファイルで表現し、それをディレクトリツリーで整理する。
これがバンドル構造です。ファイルパス自体がコンセプトのIDになります。
具体的には、例えばsales/というディレクトリの下にdatasets/、tables/、metrics/といったサブディレクトリを作り、その中にorders_db.md、orders.md、weekly_active_users.mdのようなファイルを配置します。
ディレクトリ名とファイル名が、そのまま知識の住所になるわけです。
フラットにファイルを並べるのではなく、階層を作ることでAIエージェントが「どこを読めばいいか」を判断しやすくなります。
ディレクトリの切り方自体に意味があるので、最初にどう階層を設計するかが重要になってきます。
YAMLフロントマター:typeフィールドだけが必須
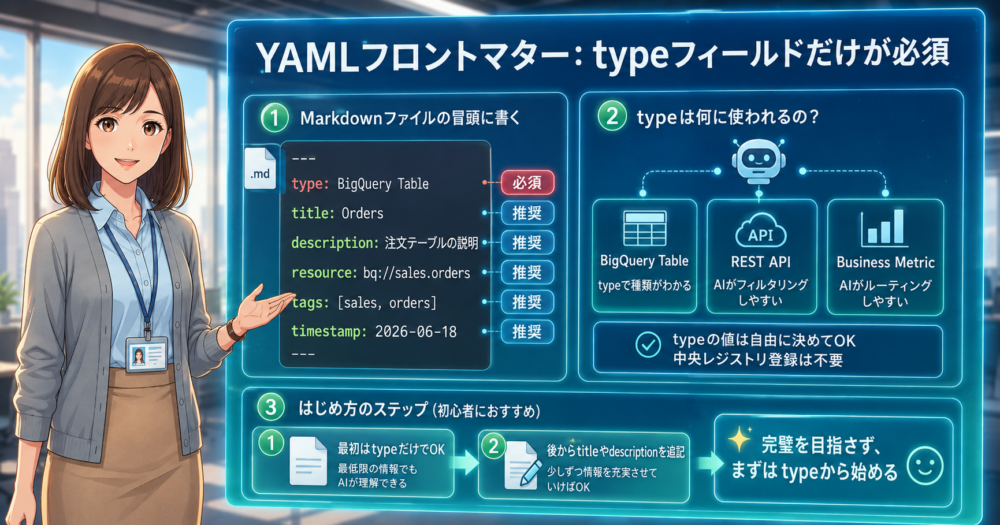
各Markdownファイルの冒頭には、YAMLフロントマターを置きます。
必須フィールドはtypeだけ。それ以外のtitle、description、resource、tags、timestampは推奨ですが省略できます。
typeフィールドには、そのコンセプトの種類を書きます。例えば「BigQuery Table」「REST API」「Business Metric」のような値です。
このtypeを使って、AIエージェントがファイルをフィルタリングしたりルーティングしたりします。
typeの値は中央レジストリに登録する必要がなく、プロデューサー(書く側)が自由に決められます。
titleやdescriptionを省略すると、AIエージェントが読んだときに判断材料が減ります。
ただし、最初から完璧に書こうとすると動けなくなるので、まずはtypeだけ書いて後から追記する、という順番でも問題ありません。
Markdownリンクでグラフ状に相互参照できる
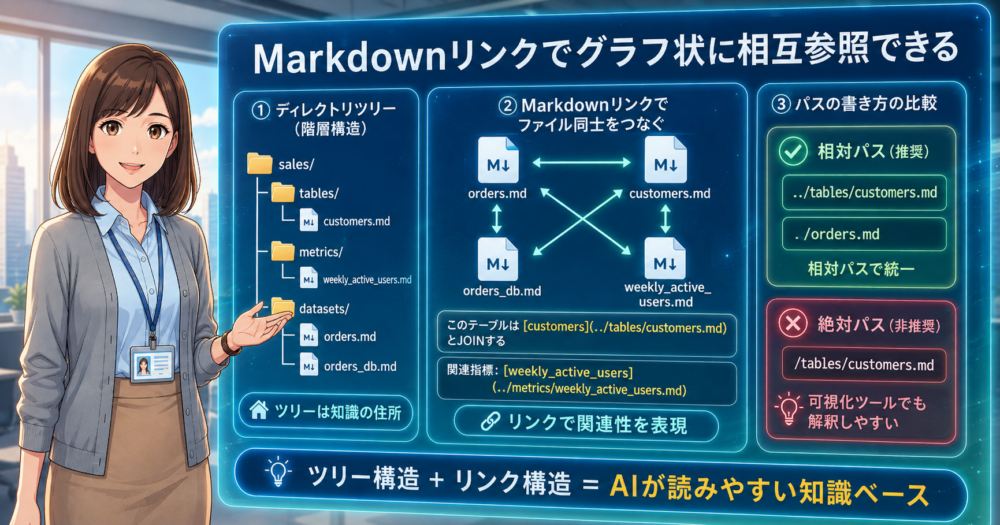
OKFではMarkdownの標準的なリンク記法を使って、ファイル同士をつなぎます。
例えば「このテーブルは[customers](/tables/customers.md)とJOINする」のように、相対パスでリンクを張るだけです。
ディレクトリツリーが階層構造なのに対し、Markdownリンクはグラフ状の相互参照を作ります。ツリー構造だけでは表現しきれない「関連性」を、リンクで補う形です。
この組み合わせが、AIエージェントにとって読みやすい知識ベースを作ります。
リンクを張るときに注意したいのは、絶対パスではなく相対パスを使うこと。
絶対パスで書いてしまうと、後述するビジュアライザーが正しく解釈できないケースが出てきます。最初から相対パスで統一しておくと、後で困りません。
OKFを書く前に決めておくべき3つの前提
 長谷川さん
長谷川さんえっ、待ってください、メモります。
書く前に決めておくことって何ですか?
高野さんここ、意外と見落としがちだから。
何をファイル化するか、階層をどう切るか、誰が更新するかの3つだよ
OKFの仕様書は「どう書くか」を説明していますが、「何を書くか」「誰が書くか」には触れていません。
でも、実際に手を動かし始めると、この3つを決めていないと手が止まります。書き始める前に、この前提を整理しておくと作業がスムーズに進みます。
最初にこの3つを決めずに書き始めると、途中で「これもファイル化すべきか?」「ディレクトリをもう一段掘るべきか?」という判断で止まってしまいます。
完璧に決める必要はないですが、仮決めでもいいので書き出す前に一度立ち止まって考えておくと、後戻りが減ります。
どの知識をファイル化するか?変化頻度と参照頻度で判断する
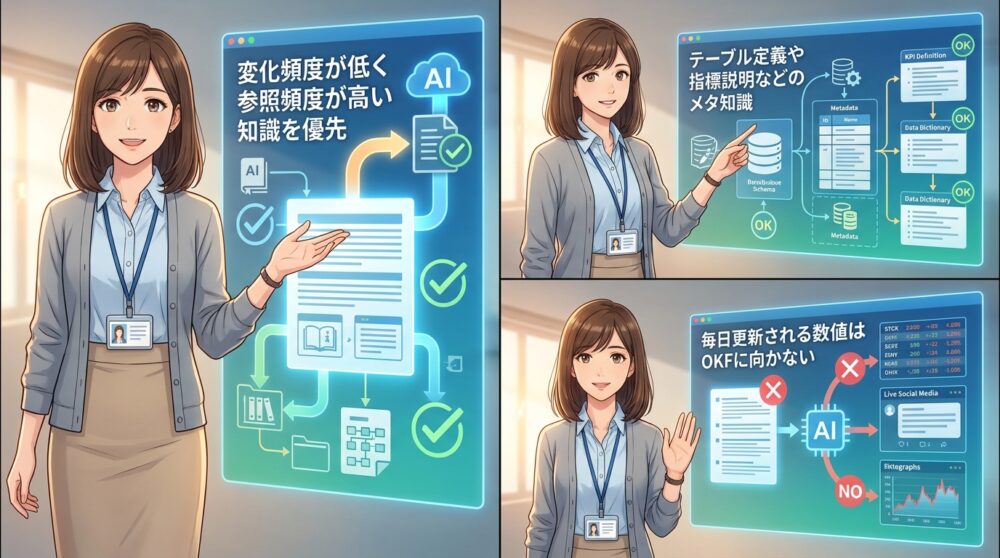
全ての情報をOKF化する必要はありません。どの知識をファイルにするかを決めるには、「変化頻度」と「参照頻度」の2軸で考えるのが現実的です。
変化頻度が高い情報、例えば毎日更新されるダッシュボードの数値や、リアルタイムで変わるステータスは、OKFに向きません。
OKFは静的なファイルで管理する仕組みなので、頻繁に書き換えが発生する情報はむしろ別のシステム(データベースやAPI)に置いた方が適切です。
逆に、変化頻度が低く、参照頻度が高い情報はOKFに向いています。例えば、テーブルスキーマの説明、APIのエンドポイント仕様、ビジネス指標の定義といったものです。
一度書いたら数ヶ月は変わらないが、エンジニアやアナリストが何度も参照する、というタイプの知識です。
- 変化頻度が低く参照頻度が高い知識を優先
- テーブル定義や指標説明などのメタ知識
- 毎日更新される数値はOKFに向かない
この基準で仕分けると、何をファイル化すべきかの判断がつきやすくなります。
迷ったら、まずは「週に一度は誰かが見る」かつ「月に一度程度しか更新しない」という情報から始めてみるのが無難です。
ディレクトリをどう切るか?階層設計の判断軸

ディレクトリの階層をどう設計するかに、正解はありません。OKFの仕様はドメイン非依存なので、組織のしかたはプロデューサーに委ねられています。ただ、迷ったときの判断軸はいくつかあります。
一つは「概念の種類で分ける」パターン。例えば、datasets/、tables/、metrics/のように、コンセプトのtypeごとにディレクトリを切る方法です。
この切り方は、AIエージェントが「テーブルだけを見たい」「指標だけを見たい」とフィルタリングしやすくなります。
もう一つは「プロジェクトやチームで分ける」パターン。
例えば、sales/、marketing/、engineering/のように、組織の境界線に沿ってディレクトリを切る方法です。
この切り方は、チームごとにメンテナンスの責任範囲を明確にしやすくなります。
- 概念の種類で分ける(tables/、metrics/)
- プロジェクトやチームで分ける(sales/、marketing/)
- 読む人が迷わない構造を優先
- 階層は深くしすぎない(3階層が目安)
どちらの切り方も正解ですが、読む人が迷わない構造を優先するのが大事です。
階層が深くなりすぎると、ファイルパスが長くなってリンクを張るときに面倒になります。
3階層くらいまでに抑えておくと、後で運用しやすいです。
誰がメンテナンスするのか──運用体制を最初に決める
OKFバンドルは、書いて終わりではなく、継続的に更新していくものです。誰が更新するのか、どのタイミングで見直すのかを最初に決めておかないと、半年後には誰も触らない状態になります。
一つの選択肢は、各チームに責任者を置く方法。
例えば、sales/ディレクトリはセールスチームのリードが更新する、engineering/ディレクトリはテックリードが更新する、といった分担です。責任範囲が明確になるので、更新漏れが起きにくくなります。
もう一つの選択肢は、データエンジニアやドキュメンテーションチームが一括で管理する方法。
この場合、各チームから変更依頼を受けて、専任の人がファイルを更新します。品質は保ちやすいですが、更新のスピードが遅くなる可能性があります。
どちらの方法を選ぶにしても、「誰が」「いつ」更新するかを明文化しておくことが大事です。
運用ルールを決めずに始めると、結局誰も更新しなくなり、OKFバンドルが放置されます。
最初にGitのCODEOWNERSファイルで担当を明記しておく、という方法も有効です。
最小バンドルを手を動かして書いてみる
 長谷川さん
長谷川さんあ、そういうことか!やってみます!
具体的にどこから書けばいいんですか?
高野さんまずはルートにindex.mdを置くところから。
3ステップで最小構成ができるよ
仕様書を読んだだけでは、実際にどう書けばいいか分かりにくいです。
ここでは、最小限のOKFバンドルを実際に書いてみます。手を動かすと、ディレクトリの切り方やリンクの張り方が体感として理解できます。
最小バンドルは3ステップで作れます。Step1でルートにindex.mdを置き、Step2でコンセプトファイルを書き、Step3でファイル同士をリンクでつなぐ。
この3ステップを順番にやっていけば、OKFの基本構造が見えてきます。
Step1:ルートにindex.mdを置く
まず、バンドルのルートディレクトリにindex.mdを作ります。このファイルはバンドル全体の入り口になります。
必須ではありませんが、AIエージェントや人間がバンドルを初めて見たとき、まずこのindex.mdを読むことで全体像を把握できるようにするのが目的です。
index.mdには、バンドルの概要、含まれるディレクトリの説明、主要なコンセプトへのリンクを書きます。YAMLフロントマターにtypeを書いてもいいですし、省略してもOKです。最初は簡単に「このバンドルには何が入っているか」を数行で書くだけで十分です。
例えば、以下のような内容を書きます。「このバンドルはsalesチームのデータカタログです。データセット、テーブル、指標の定義が含まれています。詳細は各ディレクトリ配下のindex.mdを参照してください」。シンプルですが、これだけでバンドルの全体像が伝わります。
ルートindex.mdがないと起きること
index.mdがないバンドルでも、技術的には動作します。ただ、AIエージェントが最初にどのファイルを読めばいいか分からず、ディレクトリ全体をスキャンする羽目になります。
人間にとっても、何のバンドルなのか分からないまま個別ファイルを開く手間が発生します。
index.mdは「目次」の役割を果たします。
バンドルが大きくなればなるほど、この目次の有無が効いてきます。
最初は面倒に感じるかもしれませんが、後で追加するより最初に置いておいた方が楽です。
Step2:コンセプトファイルにYAMLとMarkdownを書く
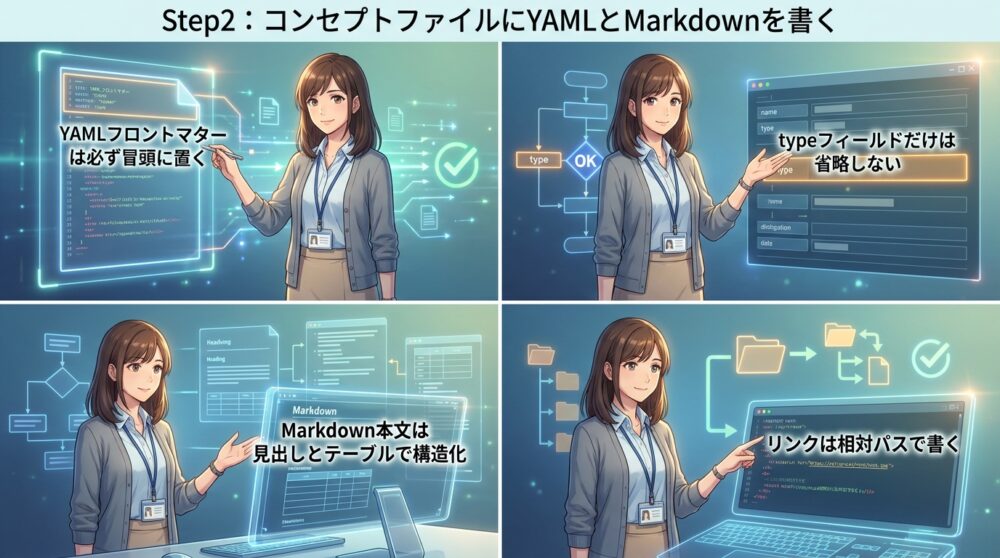
次に、実際のコンセプトファイルを1つ書いてみます。例として、tables/orders.mdというファイルを作ります。
このファイルには、ordersテーブルの定義を書きます。
ファイルの冒頭にYAMLフロントマターを置きます。
必須のtypeフィールドに「BigQuery Table」と書き、titleに「Orders」、descriptionに「One row per completed customer order.」と書きます。resourceにはBigQueryコンソールへのリンクを入れておくと、AIエージェントがリソースに直接アクセスできます。
YAMLフロントマターの後にMarkdown本文を書きます。例えば「# Schema」という見出しを作り、カラム定義をMarkdownテーブルで書きます。order_id、customer_id、order_date、amountといったカラム名と、それぞれのデータ型、説明を並べます。
- YAMLフロントマターは必ず冒頭に置く
- typeフィールドだけは省略しない
- Markdown本文は見出しとテーブルで構造化
- リンクは相対パスで書く
コンセプトファイルを書くとき、完璧を目指す必要はありません。
最初はtypeとtitleだけ書いて、後からdescriptionやresourceを追記していく形でも問題ないです。
まずは骨組みを作ることを優先してください。
コンセプトファイルの粒度をどう決めるか
1ファイル1コンセプトが原則ですが、「コンセプト」の粒度は組織によって違います。例えば、1つのテーブルを1ファイルにするのか、関連する複数テーブルを1ファイルにまとめるのか、という判断です。
迷ったら、「AIエージェントがこのファイルを読んだとき、1つの質問に答えられる情報がまとまっているか」を基準にするといいです。例えば「ordersテーブルとは何か?」という質問に答えられる情報が1ファイルに収まっていれば、それが合った粒度です。
Step3:ファイル間をリンクでつなぐ
最後に、ファイル同士をMarkdownリンクでつなぎます。例えば、orders.mdの中に「このテーブルは[customers](/tables/customers.md)とJOINする」というリンクを書きます。相対パスでリンクを張ることで、ディレクトリ全体を別の場所に移動しても、リンクが壊れません。
リンクを張るときは、相手ファイルが存在することを前提にします。
customers.mdがまだ存在しない場合は、先に空ファイルだけ作っておくか、リンクを後回しにするか、どちらでも構いません。ただし、リンク切れが大量に残っている状態は避けた方がいいです。
リンクを適切に張ると、AIエージェントが「ordersテーブルを調べたい」と思ったときに、関連するcustomersテーブルにも自動的にたどり着けます。ツリー構造だけでは表現できない「関連性」を、リンクで補完するわけです。
リンクの張りすぎに注意
リンクを張りすぎると、逆に読みにくくなります。全ての単語にリンクを張るのではなく、「ここを読めば次に必要な情報が得られる」という明確な理由があるときだけリンクを張るのが原則です。
例えば、orders.mdの中で「customer_idはcustomersテーブルの外部キー」と書いたなら、customersへのリンクを張るのは自然です。
でも、単に「顧客」という単語が出てきたからといって、全てにリンクを張る必要はありません。リンクは「次のアクション」を示すものとして使うと、ちょうどいい密度に収まります。
OKFが解決しようとしている現実
 長谷川さん
長谷川さんうわ、それ知らなかったやつだ。
OKFって具体的にどんな問題を解決してるんですか?
高野さんそう、そこ気づけたら半分終わったようなもの。
組織知識の散在問題と、エージェント構築の重複問題だよ
OKFが登場した背景には、AIエージェントが組織の業務に答えようとするときに直面する「コンテキスト組み立て問題」があります。この問題を理解すると、なぜOKFがこの形になったのか、なぜ今Googleが公開したのかが見えてきます。
OKFは単なるドキュメントフォーマットではなく、AIエージェントとの共存を前提にした知識共有の仕組みです。
仕様自体はシンプルですが、背後にある課題認識を知っておくと、どこに力を入れて構造化すべきかの判断がつきやすくなります。
組織知識が散在する「context-assembly problem」
組織内の知識は、今、バラバラな場所に存在しています。
メタデータカタログ、Wiki、共有ドライブ、コードコメント、Notion、Slackのピン留めメッセージ、シニアエンジニアの頭の中。
AIエージェントがこれらを統合して答えるには、毎回ゼロから「どこに何があるか」を探す必要があります。
この問題を「context-assembly problem(コンテキスト組み立て問題)」と呼びます。各社がベンダー独自のカタログやSDKを使っていると、エージェント構築者は毎回同じ統合作業を繰り返す羽目になります。OKFは、この重複作業を減らすための共通レイヤーを教えます。
OKFが「ベンダー中立」を強調しているのは、この文脈があるからです。特定のクラウドプラットフォームやツールに依存しないフォーマットにすることで、組織が別のツールに移行しても、OKFバンドルはそのまま使えます。
知識の「持ち運び可能性」が保証されるわけです。
暗黙知をどう扱うか
OKFは明文化された知識を扱うフォーマットです。シニアエンジニアの頭の中にしかない暗黙知は、OKFに直接入りません。
ただし、OKFバンドルを書く過程で「これ、誰かに聞かないと分からない」という箇所が明確になります。その質問を投げて、回答をファイルに書き起こせば、暗黙知が形式知に変わります。
OKFは暗黙知を抽出するツールではありませんが、暗黙知を可視化するきっかけにはなります。「このテーブルのこのカラム、なぜこういう設計になっているのか?」という疑問が浮かんだら、その答えをdescriptionやMarkdown本文に書き込むことで、次の人が同じ質問をしなくて済みます。
MCPやllms.txtとの違い──静的ナレッジを整える層
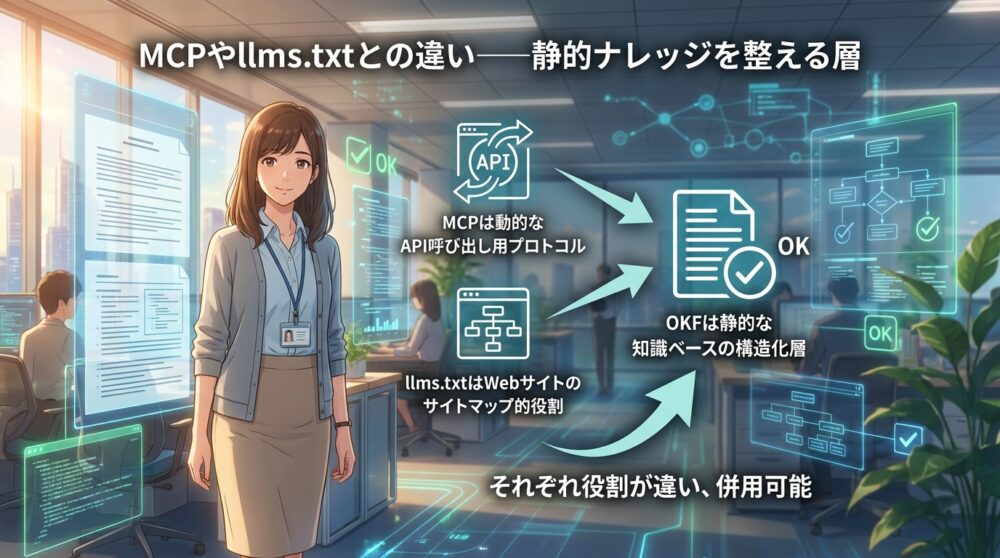
2026年時点で、AIエージェントにコンテキストを渡す方法はいくつか登場しています。Model Context Protocol(MCP)やllms.txtといったアプローチもあります。OKFはこれらとどう違うのでしょうか。
MCPは、LLMがリアルタイムでツールやAPIを呼び出すためのプロトコルです。動的なコンテキスト取得に強いです。一方、OKFは静的なファイルで知識を管理します。
毎回APIを叩かなくても、ファイルシステム上に置かれたMarkdownを読めば必要な情報が得られる、という設計です。
llms.txtは、Webサイトのルートに置く簡易的なコンテキストファイルです。
サイトマップのような役割を果たします。OKFはより構造化されたディレクトリツリーとYAMLメタデータを持ち、組織内の複雑な知識を表現できます。llms.txtが「入口」なら、OKFは「中身」かもしれません。
- MCPは動的なAPI呼び出し用プロトコル
- llms.txtはWebサイトのサイトマップ的役割
- OKFは静的な知識ベースの構造化層
- それぞれ役割が違い、併用可能
これらのアプローチは競合ではなく、役割が違います。OKFで静的な知識ベースを整え、MCPで動的なツール呼び出しを行い、llms.txtで外部エージェント向けに入口を示す、という組み合わせも考えられます。OKFは「静的ナレッジを整える層」として位置づけると分かりやすいです。
なぜ今Googleが公開したのか
OKFは2026年6月12日にGoogle Cloudから公開されました。
このタイミングには理由があります。2025年から2026年にかけて、AIエージェントが業務ツールとして実用化され始めました。それに伴い、「エージェントに何を渡すか」の課題が顕在化したからです。
Googleは自社のメタデータ管理基盤「Knowledge Catalog」との連携を前提に、OKFをオープンフォーマットとして公開しました。Knowledge Catalogの中だけで閉じた仕様にせず、外部ツールやエージェントも読める形にすることで、エコシステム全体の標準を狙っています。
実際、OKFのリポジトリにはBigQueryからOKF形式へ変換するエンリッチメントエージェントの参照実装や、GA4やStack Overflowのデータを元にしたサンプルが格納されています。
Google単独の仕様ではなく、他社も採用できるオープンな設計にすることで、業界標準を目指している意図が読み取れます。
つまずきやすいポイントと対処

OKFを実際に書き始めると、いくつか「あれ、これどうすればいいんだ?」という場面に遭遇します。
仕様書には明記されていないが、実運用で引っかかるポイントです。
ここでは、よくあるつまずきと対処法をまとめます。
これらのポイントを先に知っておけば、無駄に試行錯誤する時間を減らせます。
特に、既存のObsidianやNotionをそのまま移行しようとすると、OKFの設計思想と合わない部分が出てきます。どこを妥協して、どこを作り直すかの判断が必要になります。
絶対パスリンクが可視化ツールで無視される
Markdownリンクを絶対パス(例:`/tables/orders.md`)で書くと、一部の可視化ツールがリンクを正しく解釈できません。OKFの仕様自体は絶対パスを禁止していませんが、相対パス(例:`../tables/orders.md`や`./orders.md`)で書いた方が互換性が高いです。
特に、GitHubリポジトリでOKFバンドルを管理している場合、絶対パスはリポジトリのルートからの絶対パスとして解釈されることがあります。バンドルのルートがリポジトリのルートと一致していればいいですが、サブディレクトリにバンドルを置いている場合、リンクが壊れます。
対処法は簡単で、最初から相対パスで統一しておくことです。ファイルを書くときに「このファイルから見て、リンク先はどこにあるか」を考えてパスを書けば、後で困りません。エディタの補完機能を使えば、相対パスも手間なく書けます。
既存リンクを一括変換するスクリプト
すでに絶対パスで書いてしまったリンクが大量にある場合、手作業で直すのは現実的ではありません。そういうときは、sedやawkで一括置換するスクリプトを書くか、Markdownパーサーを使って自動修正するツールを作ると楽です。
例えば、Pythonでmarkdownライブラリを使い、全ファイルのリンクを抽出して相対パスに書き換えるスクリプトを10行程度で書けます。一度作っておけば、今後同じ問題が起きたときに使い回せます。
既存ObsidianやNotionをそのままOKF化できない理由

ObsidianやNotionで既にナレッジベースを作っている場合、「これをそのままOKF形式に変換できないか?」と考える人は多いです。結論から言うと、部分的には可能ですが、そのままは無理です。理由はメタデータの違いです。
ObsidianのMarkdownファイルは、YAMLフロントマターを持っていることがありますが、OKFが必須とするtypeフィールドは大抵含まれていません。Notionのページは階層構造を持っていますが、Notion独自のブロックIDやデータベースプロパティがあり、Markdownにエクスポートした時点でその構造が失われます。
対処法としては、既存のMarkdownをベースにしつつ、typeフィールドを後から追加する方法があります。全ファイルに手作業でtypeを書き込むのは大変なので、スクリプトでファイル名やディレクトリ名からtypeを推測して自動追記するのが現実的です。
- ObsidianのYAMLにはtypeフィールドがない
- Notionのブロック構造はMarkdown変換で失われる
- ファイル名やディレクトリ名からtypeを推測して自動追記
- 既存リンクは相対パスに修正が必要
完璧な自動変換は難しいですが、8割方は自動化できます。残り2割は手作業で調整する覚悟で進めると、現実的な移行計画になります。
log.mdとindex.mdをいつ使うか迷う
OKFにはlog.mdという特殊なファイルがあります。これは、バンドル全体の更新履歴を時系列で記録するためのファイルです。index.mdが「目次」なら、log.mdは「更新履歴」です。
ただし、どちらも必須ではないので、いつ使うべきか迷います。
index.mdは、バンドルが複数のディレクトリを含む場合に作った方がいいです。
特に、初めてバンドルを見る人やAIエージェントが「まず何を読めばいいか」を示す意味で有用です。逆に、バンドルが単一ディレクトリで完結している場合、index.mdがなくても困りません。
log.mdは、バンドルの変更頻度が高い場合に作ると役立ちます。
Gitのコミット履歴でも更新履歴は追えますが、log.mdにはコミットログよりも高レベルな「何が変わったか」の要約を書きます。
例えば「2026年6月にmetricsディレクトリを追加」「2026年7月にtablesのスキーマ定義を更新」といった内容です。
log.mdを書くタイミング
log.mdは、バンドル全体に影響する大きな変更があったときに書くのが適切です。個別ファイルの細かい修正まで全てlog.mdに書くと、すぐに肥大化して読みにくくなります。
重要なマイルストーンだけを記録する、という方針で運用すると、log.mdが本来の役割を果たします。
逆に、log.mdがないからといって困ることは少ないです。最初はlog.mdなしで始めて、後で必要だと感じたら追加する、という順番でも問題ありません。完璧主義にならず、必要に応じて育てていく姿勢が大事です。
OKFに対応したツール
OKFは2026年6月に公開されたばかりなので、対応ツールはまだ少ないです。ただし、Googleが公式に提供しているビジュアライザーや、コミュニティで開発されているツールがいくつか出始めています。
公式ツールとしては、OKFバンドルをグラフ状に可視化するビジュアライザーがあります。これはブラウザ上で動作し、ディレクトリツリーとMarkdownリンクの関係を視覚的に確認できます。
バンドルが大きくなってきたときに、全体の構造を俯瞰するのに役立ちます。
エンリッチメントエージェントも公式が参照実装を公開しています。
これは、BigQueryのメタデータを自動的にOKF形式に変換するツールです。
手作業でファイルを書かなくても、既存のデータベーススキーマからOKFバンドルを生成できます。
同様のツールを他のデータソース(PostgreSQL、Snowflake等)向けに作るのも可能です。
- 公式ビジュアライザーでバンドル構造を可視化
- エンリッチメントエージェントで自動変換
- ObsidianやVS Code等の既存エディタで編集可
- GitHubでバージョン管理して共同編集
編集ツールとしては、特別なものは不要です。
ObsidianやVS Code、Typoraといった既存のMarkdownエディタで十分です。
OKFは標準的なMarkdownを使っているので、どのエディタでも編集できます。
GitHubやGitLabでバージョン管理すれば、複数人での共同編集も可能です。
AIドキュメント作成支援ツールのおすすめ3選
ここまでの内容を踏まえて、実際に使えるAIドキュメント作成支援ツールを3つ紹介します。それぞれ特徴が違うので、自分の用途に合うものを選んでください。
Notion AI
| ツール名 | Notion AI |
| 無料プラン | 要確認 |
| 料金プラン | 公式サイトで最新情報を確認 |
| 公式サイト | Notion AI公式サイト |
Notion AIはAIに読ませやすいドキュメントの書き方「OKF」に関連するツールの一つです。具体的な機能や料金プランは公式サイトをご確認ください。
ChatGPT
| ツール名 | ChatGPT |
| 無料プラン | 要確認 |
| 料金プラン | 公式サイトで最新情報を確認 |
| 公式サイト | ChatGPT公式サイト |
ChatGPTは、OpenAIが開発した対話型のAIツールで、自然な文章でのやり取りを通じて情報収集や文章作成をサポートします。AIに読ませやすいドキュメントを作成する際には、ChatGPTに質問を投げかけながら文章を整理したり、曖昧な表現を明確にしたりする使い方が効果的です。
箇条書きや見出しを含む構造化された文章の生成が得意で、プロンプト次第で出力形式を柔軟に調整できるため、OKF形式に沿った文章の下書きやリライトにも活用できます。ただし生成される内容は必ずしも正確とは限らないため、事実確認は人の手で行う必要があります。
幅広い用途に対応できる汎用性の高さから、AIとの対話に慣れていない初心者から、業務で本格的に文章作成を効率化したい人まで、多様なユーザーに利用されています。
Claude

| ツール名 | Claude |
| 無料プラン | 要確認 |
| 料金プラン | 公式サイトで最新情報を確認 |
| 公式サイト | Claude公式サイト |
Claudeは長文の読解力と構造化された情報の処理に優れたAIアシスタントで、OKF形式のドキュメントを扱う際に特に力を発揮します。目的・前提知識・事実を明確に分けて記述されたドキュメントを正確に理解し、文脈を踏まえた適切な回答を生成できる点が特徴です。
プロジェクト機能を使えば複数のドキュメントを参照しながら一貫性のある応答を得られるため、技術文書やマニュアルの作成支援、複雑な情報の整理といった用途に向いています。会話の履歴を保持しながら段階的に情報を深掘りできるので、ドキュメントの構成を練る際のブレインストーミングパートナーとしても活用できます。
AIに読ませることを前提とした明快な文書作成を目指す方にとって、実用的な選択肢となるでしょう。
まとめ

OKFで一番大事なのは、完璧なドキュメントを最初から書こうとしないことです。どのディレクトリ構造が正解か、どこまでメタデータを埋めるべきか、完璧に決めてから始めようとすると、永遠に動けません。
最初はtypeフィールドだけ書いて、ファイルを置く。リンクは後から張る。そのくらいの姿勢で始めた方が、結果的にバンドルが育ちます。
完璧を目指さず、必要に応じて継続的に改善していく運用が、OKFの設計思想にも合っています。
AIエージェントは、完璧なドキュメントがなくても、ある程度の情報があれば答えを返します。まずは最小バンドルを作って、実際にエージェントに読ませてみる。
その反応を見ながら、足りない情報を補っていく。その繰り返しが、実用的なOKFバンドルを作る近道です。
構造化を後回しにしてきたツケは、いつか必ず回ってきます。でも、今から少しずつ整えていけば、半年後には「あのとき始めておいてよかった」と思える状態になっているはずです。

コメント